Oops! Something went wrong while submitting the form.
We use cookies to improve your browsing experience on our website, to show you personalised content and to analize our website traffic. By browsing our website, you consent to our use of cookies. Read privacy policy.
This post gives a brief introduction to Cloudflare Workers and Cloudflare KV store. They address a fairly common set of problems around scaling an application globally. There are standard ways of doing this but they usually require a considerable amount of upfront engineering work and developers have to be aware of the 'scalability' issues to some degree. Serverless application tools target easy scalability and quick response times around the globe while keeping the developers focused on the application logic rather than infra nitty-gritties.
Global responsiveness
When an application is expected to be accessed around the globe, requests from users sitting in different time-zones should take a similar amount of time. There can be multiple ways of achieving this depending upon how data intensive the requests are and what those requests actually do.
Data intensive requests are harder and more expensive to globalize, but again not all the requests are same. On the other hand, static requests like getting a documentation page or a blog post can be globalized by generating markup at build time and deploying them on a CDN.
And there are semi-dynamic requests. They render static content either with some small amount of data or their content change based on the timezone the request came from.
The above is a loose classification of requests but there are exceptions, for example, not all the static requests are presentational.
Serverless frameworks are particularly useful in scaling static and semi-static requests.
Cloudflare Workers Overview
Cloudflare worker is essentially a function deployment service. They provide a serverless execution environment which can be used to develop and deploy small(although not necessarily) and modular cloud functions with minimal effort.
It is very trivial to start with workers. First, lets install wrangler, a tool for managing Cloudfare Worker projects.
Wrangler handles all the standard stuff for you like project generation from templates, build, config, publishing among other things.
A worker primarily contains 2 parts: an event listener that invokes a worker and an event handler that returns a response object. Creating a worker is as easy as adding an event listener to a button.
can be used to take a live preview on the browser. The preview is only meant to be used for testing(either by you or others). If you want the workers to be triggered by your own domain or a workers.dev subdomain, you need to publish it.
Publishing is fairly straightforward and requires very less configuration on both wrangler and your project.
Wrangler Configuration
Just create an account on Cloudflare and get API key. To configure wrangler, just do:
It will ask for the registered email and API key, and you are good to go.
To publish your worker on a workers.dev subdomain, just fill your account ID in the wrangler.toml and hit wrangler publish. The worker will be deployed and live at a generated workers.dev subdomain.
Regarding Routes
When you publish on a {script-name}.{subdomain}.workers.dev domain, the script or project associated with script-name will be invoked. There is no way to call a script just from {subdomain}.workers.dev.
Worker KV
Workers alone can't be used to make anything complex without any persistent storage, that's where Workers KV comes into the picture. Workers KV as it sounds, is a low-latency, high-volume, key-value store that is designed for efficient reads.
It optimizes the read latency by dynamically spreading the most frequently read entries to the edges(replicated in several regions) and storing less frequent entries centrally.
Newly added keys(or a CREATE) are immediately reflected in every region while a value change in the keys(or an UPDATE) may take as long as 60 seconds to propagate, depending upon the region.
Workers KV is only available to paid users of Cloudflare.
Writing Data in Workers KV
KV is organized into namespaces each of which can hold upto 1 billion KV pairs. Both Key and Value can be arbitrary byte sequences. First, we will create the namespace. Actions like creating the namespace, writing pairs, can be done either by the KV API or from the web interface provided on the Cloudflare's dashboard. We will be using this API: CODE: https://gist.github.com/velotiotech/c3cc131e34894fe7aba8211c554cadc6.js
Now we can write KV pairs in this namespace. The following HTTP requests will do the same:
Here the NAMESPACE_ID is the same ID that we received in the last request. First-key is the key name and the My first value is the value.
Let’s complicate things a little
Above overview just introduces the managed cloud workers with a 'hello world' app and basics of the Workers KV, but now let’s make something more complicated. We will make an app which will tell how many requests have been made from your country till now. For example, if you pinged the worker from the US then it will return number of requests made so far from the US.
We will need:
Some place to store the count of requests for each country.
Find from which country the Worker was invoked.
For the first part, we will use the Workers KV to store the count for every request.
Let's start
First, we will create a new project using wrangler: wrangler generate request-count.
We will be making HTTP calls to write values in the Workers KV, so let's add 'node-fetch' to the project:
Now, how do we find from which country each request is coming from? The answer is the cf object that is provided with each request to a worker.
The cf object is a special object that is passed with each request and can be accessed with request.cf. This mainly contains region specific information along with TLS and Auth information. The details of what is provided in the cf, can be found here.
As we can see from the documentation, we can get country from
The cf object is not correctly populated in the wrangler preview, you will need to publish your worker in order to test cf's usage. An open issue mentioning the same can be found here.
Now, the logic is pretty straightforward here. When we get a request from a country for which we don't have an entry in the Worker's KV, we make an entry with value 1, else we increment the value of the country key.
To use Workers KV, we need to create a namespace. A namespace is just a collection of key-value pairs where all the keys have to be unique.
A namespace can be created under the KV tab in Cloudflare web UI by giving the name or using the API call above. You can also view/browse all of your namespaces from the web UI. Following API call can be used to read the value of a key from a namespace:
But, it is neither the fastest nor the easiest way. Cloudflare provides a better and faster way to read data from your namespaces. It’s called binding. Each KV namespace can be bound to a worker script so to make it available in the script by the variable name. Any namespace can be bound with any worker. A KV namespace can be bound to a worker by going to the editing menu of a worker from the Cloudflare UI.
Following steps show you how to bind a namespace to a worker:
Go to the edit page of the worker in Cloudflare web UI and click on the KV tab:
Then add a binding by clicking the ‘Add binding’ button.
You can select the namespace name and the variable name by which it will be bound. More details can be found here. A binding that I’ve made can be seen in the above image.
That's all we need to get this to work. Following is the relevant part of the script:
This small application also demonstrates some of the practical aspects of the workers. For example, you would notice that the updates take some time to get reflected and response time of the workers is quick, especially when they are deployed on a .workers.dev subdomain here.
Side note: You will have to recreate the namespace-worker binding everytime you deploy the worker or you do wrangler publish.
Workers vs. AWS Lambda
AWS Lambda has been a major player in the serverless market for a while now. So, how is Cloudflare Workers as compared to it? Let’s see.
Architecture:
Cloudflare Workers `Isolates` instead of a container based underlying architecture. `Isolates` is the technology that allows V8(Google Chrome’s JavaScript Engine) to run thousands of processes on a single server in an efficient and secure manner. This effectively translates into faster code execution and lowers memory usage. More details can be found here.
Price:
The above mentioned architectural difference allows Workers to be significantly cheaper than Lambda. While a Worker offering 50 milliseconds of CPU costs $0.50 per million requests, the equivalent Lambda costs $1.84 per million. A more detailed price comparison can be found here.
Speed:
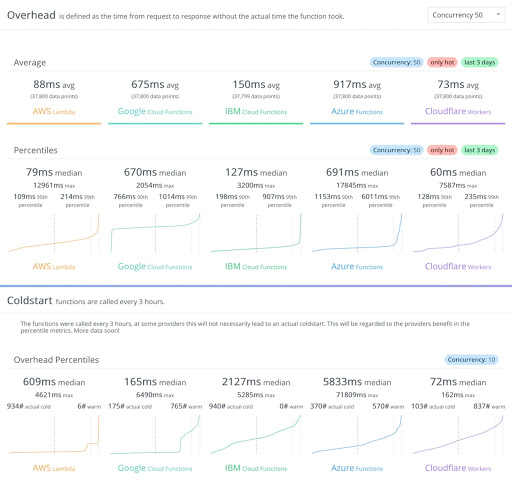
Workers also show significantly better performance numbers than Lambda and Lambda@Edge. Tests run by Cloudflare claim that they are 441% faster than Lambda and 192% faster than Lambda@Edge. A detailed performance comparison can be found here.
As we have seen, Cloudflare Workers along with the KV Store does make it very easy to start with a serverless application. They provide fantastic performance while using less cost along with intuitive deployment. These properties make them ideal for making globally accessible serverless applications.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
An Introduction To Cloudflare Workers And Cloudflare KV store
Cloudflare Workers
This post gives a brief introduction to Cloudflare Workers and Cloudflare KV store. They address a fairly common set of problems around scaling an application globally. There are standard ways of doing this but they usually require a considerable amount of upfront engineering work and developers have to be aware of the 'scalability' issues to some degree. Serverless application tools target easy scalability and quick response times around the globe while keeping the developers focused on the application logic rather than infra nitty-gritties.
Global responsiveness
When an application is expected to be accessed around the globe, requests from users sitting in different time-zones should take a similar amount of time. There can be multiple ways of achieving this depending upon how data intensive the requests are and what those requests actually do.
Data intensive requests are harder and more expensive to globalize, but again not all the requests are same. On the other hand, static requests like getting a documentation page or a blog post can be globalized by generating markup at build time and deploying them on a CDN.
And there are semi-dynamic requests. They render static content either with some small amount of data or their content change based on the timezone the request came from.
The above is a loose classification of requests but there are exceptions, for example, not all the static requests are presentational.
Serverless frameworks are particularly useful in scaling static and semi-static requests.
Cloudflare Workers Overview
Cloudflare worker is essentially a function deployment service. They provide a serverless execution environment which can be used to develop and deploy small(although not necessarily) and modular cloud functions with minimal effort.
It is very trivial to start with workers. First, lets install wrangler, a tool for managing Cloudfare Worker projects.
Wrangler handles all the standard stuff for you like project generation from templates, build, config, publishing among other things.
A worker primarily contains 2 parts: an event listener that invokes a worker and an event handler that returns a response object. Creating a worker is as easy as adding an event listener to a button.
can be used to take a live preview on the browser. The preview is only meant to be used for testing(either by you or others). If you want the workers to be triggered by your own domain or a workers.dev subdomain, you need to publish it.
Publishing is fairly straightforward and requires very less configuration on both wrangler and your project.
Wrangler Configuration
Just create an account on Cloudflare and get API key. To configure wrangler, just do:
It will ask for the registered email and API key, and you are good to go.
To publish your worker on a workers.dev subdomain, just fill your account ID in the wrangler.toml and hit wrangler publish. The worker will be deployed and live at a generated workers.dev subdomain.
Regarding Routes
When you publish on a {script-name}.{subdomain}.workers.dev domain, the script or project associated with script-name will be invoked. There is no way to call a script just from {subdomain}.workers.dev.
Worker KV
Workers alone can't be used to make anything complex without any persistent storage, that's where Workers KV comes into the picture. Workers KV as it sounds, is a low-latency, high-volume, key-value store that is designed for efficient reads.
It optimizes the read latency by dynamically spreading the most frequently read entries to the edges(replicated in several regions) and storing less frequent entries centrally.
Newly added keys(or a CREATE) are immediately reflected in every region while a value change in the keys(or an UPDATE) may take as long as 60 seconds to propagate, depending upon the region.
Workers KV is only available to paid users of Cloudflare.
Writing Data in Workers KV
KV is organized into namespaces each of which can hold upto 1 billion KV pairs. Both Key and Value can be arbitrary byte sequences. First, we will create the namespace. Actions like creating the namespace, writing pairs, can be done either by the KV API or from the web interface provided on the Cloudflare's dashboard. We will be using this API: CODE: https://gist.github.com/velotiotech/c3cc131e34894fe7aba8211c554cadc6.js
Now we can write KV pairs in this namespace. The following HTTP requests will do the same:
Here the NAMESPACE_ID is the same ID that we received in the last request. First-key is the key name and the My first value is the value.
Let’s complicate things a little
Above overview just introduces the managed cloud workers with a 'hello world' app and basics of the Workers KV, but now let’s make something more complicated. We will make an app which will tell how many requests have been made from your country till now. For example, if you pinged the worker from the US then it will return number of requests made so far from the US.
We will need:
Some place to store the count of requests for each country.
Find from which country the Worker was invoked.
For the first part, we will use the Workers KV to store the count for every request.
Let's start
First, we will create a new project using wrangler: wrangler generate request-count.
We will be making HTTP calls to write values in the Workers KV, so let's add 'node-fetch' to the project:
Now, how do we find from which country each request is coming from? The answer is the cf object that is provided with each request to a worker.
The cf object is a special object that is passed with each request and can be accessed with request.cf. This mainly contains region specific information along with TLS and Auth information. The details of what is provided in the cf, can be found here.
As we can see from the documentation, we can get country from
The cf object is not correctly populated in the wrangler preview, you will need to publish your worker in order to test cf's usage. An open issue mentioning the same can be found here.
Now, the logic is pretty straightforward here. When we get a request from a country for which we don't have an entry in the Worker's KV, we make an entry with value 1, else we increment the value of the country key.
To use Workers KV, we need to create a namespace. A namespace is just a collection of key-value pairs where all the keys have to be unique.
A namespace can be created under the KV tab in Cloudflare web UI by giving the name or using the API call above. You can also view/browse all of your namespaces from the web UI. Following API call can be used to read the value of a key from a namespace:
But, it is neither the fastest nor the easiest way. Cloudflare provides a better and faster way to read data from your namespaces. It’s called binding. Each KV namespace can be bound to a worker script so to make it available in the script by the variable name. Any namespace can be bound with any worker. A KV namespace can be bound to a worker by going to the editing menu of a worker from the Cloudflare UI.
Following steps show you how to bind a namespace to a worker:
Go to the edit page of the worker in Cloudflare web UI and click on the KV tab:
Then add a binding by clicking the ‘Add binding’ button.
You can select the namespace name and the variable name by which it will be bound. More details can be found here. A binding that I’ve made can be seen in the above image.
That's all we need to get this to work. Following is the relevant part of the script:
This small application also demonstrates some of the practical aspects of the workers. For example, you would notice that the updates take some time to get reflected and response time of the workers is quick, especially when they are deployed on a .workers.dev subdomain here.
Side note: You will have to recreate the namespace-worker binding everytime you deploy the worker or you do wrangler publish.
Workers vs. AWS Lambda
AWS Lambda has been a major player in the serverless market for a while now. So, how is Cloudflare Workers as compared to it? Let’s see.
Architecture:
Cloudflare Workers `Isolates` instead of a container based underlying architecture. `Isolates` is the technology that allows V8(Google Chrome’s JavaScript Engine) to run thousands of processes on a single server in an efficient and secure manner. This effectively translates into faster code execution and lowers memory usage. More details can be found here.
Price:
The above mentioned architectural difference allows Workers to be significantly cheaper than Lambda. While a Worker offering 50 milliseconds of CPU costs $0.50 per million requests, the equivalent Lambda costs $1.84 per million. A more detailed price comparison can be found here.
Speed:
Workers also show significantly better performance numbers than Lambda and Lambda@Edge. Tests run by Cloudflare claim that they are 441% faster than Lambda and 192% faster than Lambda@Edge. A detailed performance comparison can be found here.
As we have seen, Cloudflare Workers along with the KV Store does make it very easy to start with a serverless application. They provide fantastic performance while using less cost along with intuitive deployment. These properties make them ideal for making globally accessible serverless applications.
Velotio Technologies is an outsourced software product development partner for top technology startups and enterprises. We partner with companies to design, develop, and scale their products. Our work has been featured on TechCrunch, Product Hunt and more.
We have partnered with our customers to built 90+ transformational products in areas of edge computing, customer data platforms, exascale storage, cloud-native platforms, chatbots, clinical trials, healthcare and investment banking.
Since our founding in 2016, our team has completed more than 90 projects with 220+ employees across the following areas:
Building web/mobile applications
Architecting Cloud infrastructure and Data analytics platforms




















.svg)
.svg)